MENUCLOSE


Publications
Search on Google Scholar for details
List of all published papers by NICT
Publications
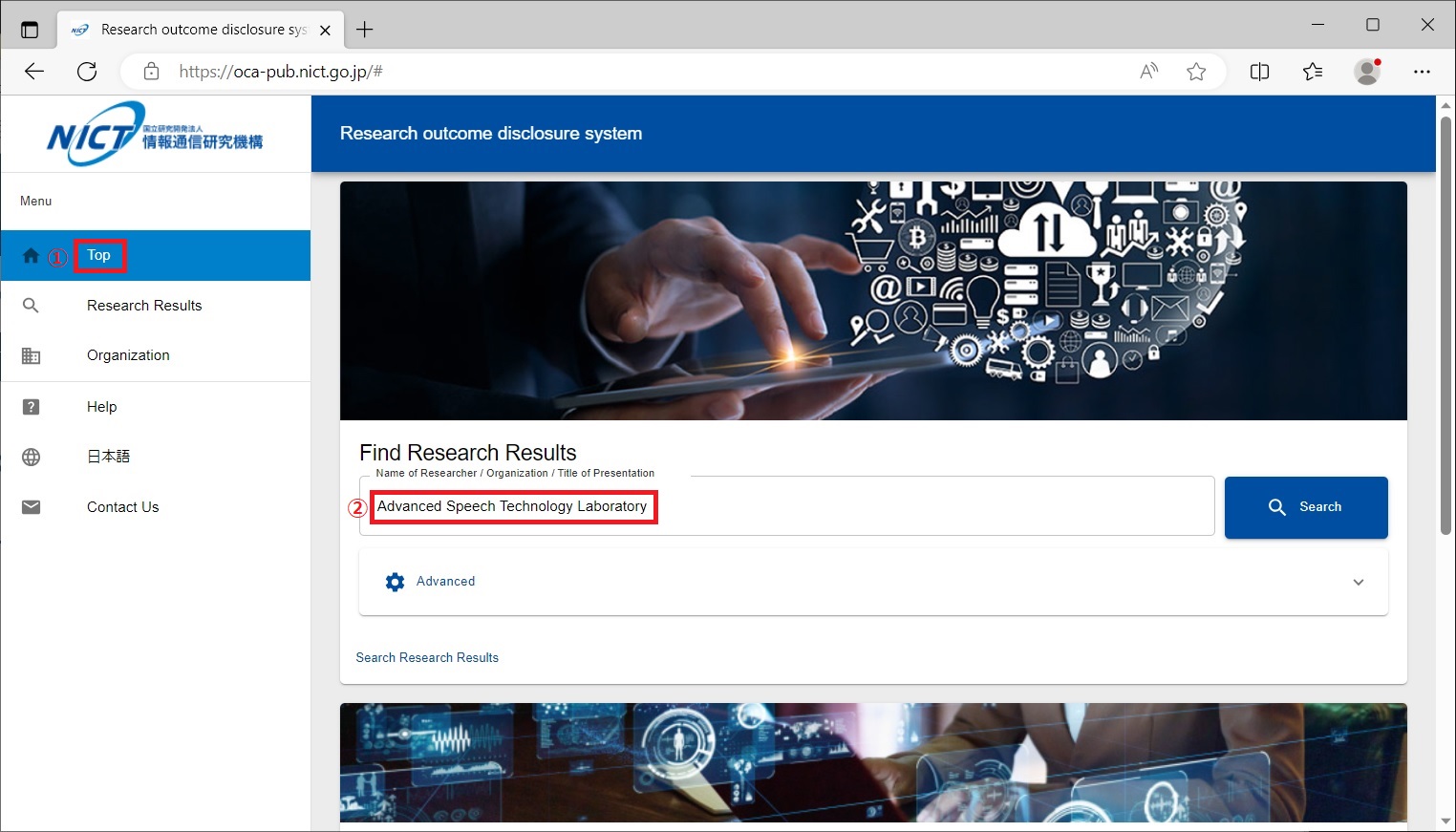
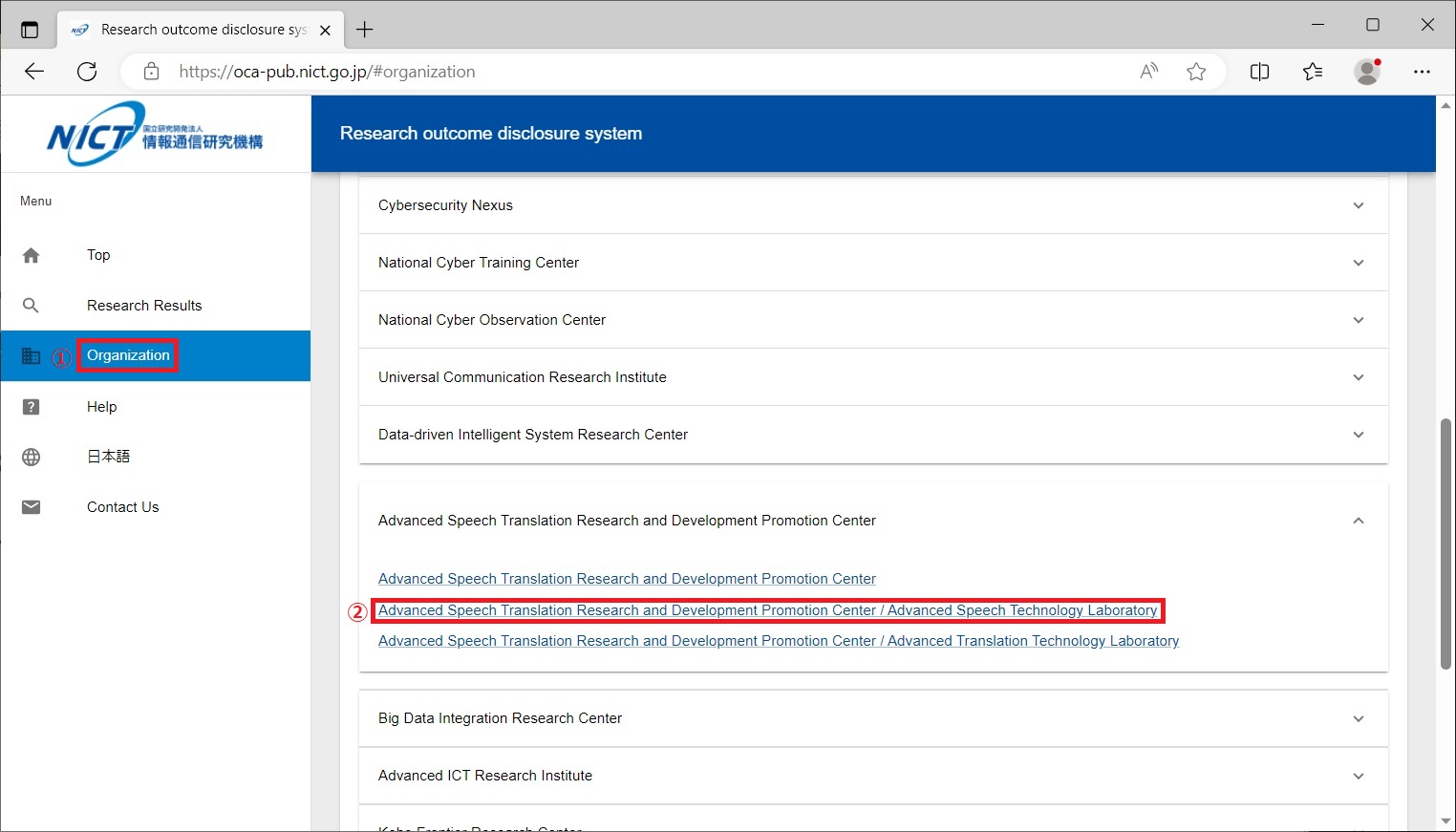
You can search papers from List of all published papers by NICT on the NICT Research outcome disclosure system.Select 'Organization' from the menu and select Advanced Speech Translation Research and Development Promotion Center / Advanced Speech Technology Laboratory under Universal Communication Research Institute.
For papers published earlier than March 2021, select 'Top' on the menu and type in "Advanced Speech Technology Laboratory".