Demo samples: Multi-stream HiFi-GAN with data-driven waveform decomposition
T. Okamoto, T. Toda and H. Kawai,
"Multi-stream HiFi-GAN with data-driven waveform decomposition,"
in Proc. ASRU, Dec 2021, pp. 610–617. [IEEE Xplore] [Preprint (PDF)]
Proposed Multi-stream HiFi-GAN generator trained using the same discriminators as original HiFi-GAN
Proposed Multi-stream HiFi-GAN can accelerate the inference speed while keeping the synthesis quality
(a): Transposed convolution [as used in original HiFi-GAN], (b): Interpolation + Convolution, (c): Sub-pixel convolution
Multi-speaker models are trained using JVS corpus
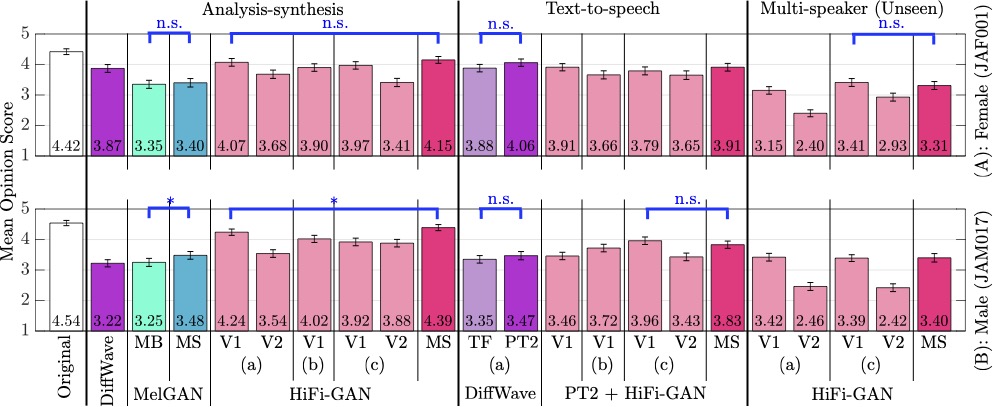
Audio Samples
Analysis-synthesis condition
Female (JAF001)
Original
Sub-DiffWave (25 iterations)
Multi-band MelGAN
Multi-stream MelGAN
HiFi-GAN V1 (a)
HiFi-GAN V2 (a)
Multi-stream HiFi-GAN
Male (JAM017)
Original
Sub-DiffWave (25 iterations)
Multi-band MelGAN
Multi-stream MelGAN
HiFi-GAN V1 (a)
HiFi-GAN V2 (a)
Multi-stream HiFi-GAN
Text-to-speech condition (Parallel Tacotron 2 with forced alignment)
Female (JAF001)
Sub-DiffWave (25 iterations)
HiFi-GAN V1 (a)
Milti-stream HiFi-GAN
Male (JAM017)
Sub-DiffWave (25 iterations)
HiFi-GAN V1 (a)
Milti-stream HiFi-GAN
Multi-speaker condition (analysis-synthesis of unseen speaker)
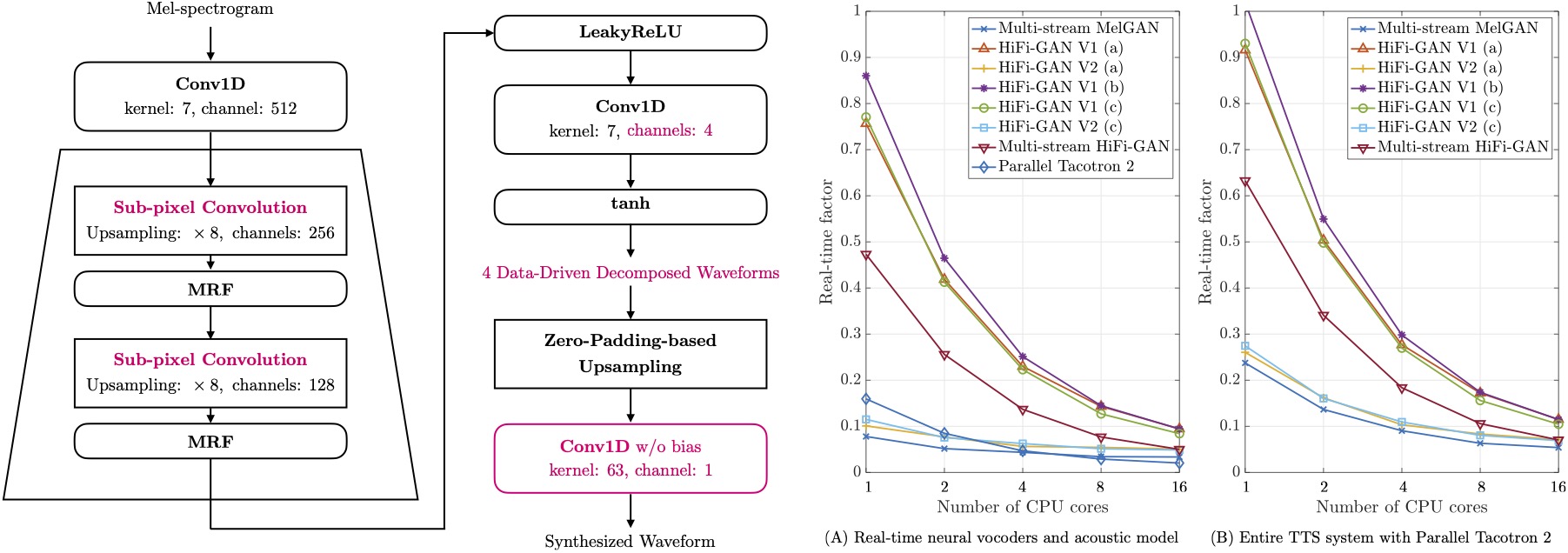 Proposed Multi-stream HiFi-GAN generator trained using the same discriminators as original HiFi-GAN
Proposed Multi-stream HiFi-GAN generator trained using the same discriminators as original HiFi-GAN
 (a): Transposed convolution [as used in original HiFi-GAN], (b): Interpolation + Convolution, (c): Sub-pixel convolution
(a): Transposed convolution [as used in original HiFi-GAN], (b): Interpolation + Convolution, (c): Sub-pixel convolution